[자료구조/알고리즘 이론] LCS 알고리즘(Longest Common Subsequence Algorithm)

🎮LCS만 검색하면 롤 북미 프로 리그가 나오던데,,, 이거 아닙니다!
LCS 알고리즘
LCS 알고리즘은 문자열 혹은 배열 내에서 가장 긴 공통 부분 수열을 찾는 알고리즘입니다. 여기서 공통 부분 수열이란 수열(문자열/배열) 내의 원소 내에서 순서대로 나타나지만 반드시 연속될 필요는 없는 부분 수열을 뜻합니다.
LCS는 두 문서가 얼마나 비슷한지를 확인하는 코드 비교 도구, 버전 관리 시스템에 응용되거나 생물정보학의 서열 간 유사성 조사를 위해 DNA, RNA 서열 분석에 응용됩니다.
설명을 위해 그림으로 설명하겠습니다. 아래와 같이 두 문자열이 존재한다고 가정해봅시다.

두 문자열 내에서 공통으로 존재하는 문자열은 ABEFG입니다. 해당 문자열은 두 문자열 내에서 반드시 나타나지만 반드시 연속해서 나타나지는 않습니다. 따라서 LCS입니다.
다음 예시를 한 번 봅시다. 아래는 숫자로 이루어진 순열입니다. 두 수열 내에서 반드시 나타나지만 반드시 연속해서 나타나지는 않는 수열은 8763입니다.

즉 부분수열들이 인접하게, 연속으로 나타나지 않아도 되며 공통적으로 존재하는 부분수열을 순서대로 합쳐서 표기한 것이 LCS라고 생각하시면 되겠습니다.
LCS 알고리즘 구현
LCS가 뭔지는 어렴풋이 이해되는데 어떻게 구현해야 할까요? LCS 알고리즘은 기본적으로 다이나믹 프로그래밍(Dynamic Programming, DP) 기반의 알고리즘입니다. 두 문자열 X와 Y가 주어졌다고 가정합시다. LCS[i][j]는 문자열 X의 i인덱스, 문자열 Y의 j인덱스 까지의 공통 부분 수열의 최대 값입니다.
부분 수열 비교 시 두 가지 조건으로 나누어 이를 점화식으로 나타낼 수 있습니다.
조건 1: X의 i번째 문자와 Y의 j번째 문자가 동일한 경우(같은 인덱스의 문자가 동일한 경우)
- 이 경우 LCS[i][j]는 X와 Y의 첫 i-1개와 j-1개의 최장 공통 부분 수열에 현재 문자를 추가한 것과 같습니다.
수식으로 표현하면 LCS[i][j] = LCS[i-1][j-1] + 1이 되는 것이죠.
- X 문자열: "ABC"
- Y 문자열: "AEC"인 경우, X[2] == Y[2] 이므로 LCS[3][3] = LCS[2][2] + 1이 됩니다.
여기서 LCS[2][2]는 공통 문자열이 "A" 하나이므로 1이 됩니다. 따라서 LCS[3][3] = 1 + 1 = 2가 됩니다.
조건 2: X의 i번째 문자와 Y의 j번째 문자가 다른 경우(같은 인덱스의 문자가 다른 경우)
- 이 경우 LCS[i][j]는 X의 첫 i-1개의 문자와 Y의 첫 j개 문자 사이의 최장 공통 부분 수열의 길이와 X의 첫 i개 문자와 Y의 첫 j-1개 문자 사이의 최장 공통 부분 수열의 길이 중 더 큰 값이 됩니다.
수식으로 표현하면 LCS[i][j] = max(LCS[i][j-1], LCS[i-1][j]) 가 되는 것이죠.
- X 문자열: "ABC"
- Y 문자열: "ADQ"인 경우, X[2] != Y[2] 이므로 LCS[3][3] = max(LCS[2][3], LCS[3][2])가 됩니다.
여기서 LCS[2][3]은 "AB"와 "ADQ" 사이의 최장 부분 수열의 길이입니다. LCS[3][2]는 "ABC"와 "AD" 사이의 최장 공통 부분 수열의 길이입니다. LCS[2][3]의 공통 부분 수열은 "A", LCS[3][2]의 공통 부분 수열도 "A" 이므로 둘의 길이는 같고, LCS[3][3]은 1이 됩니다.
이러나저러나 과거의 공통 문자열 길이가 현재 공통 문자열 길이에 영향을 끼친다는 점은 같습니다. 인덱스의 문자가 같다면 이전 인덱스의 문자열의 길이 + 1, 아니라면 이전 인덱스 문자열 길이 중 더 긴 문자열을 선택하는 것이죠. 즉 같은 계산을 반복할 필요 없이 이전 계산의 결과 값을 재활용한다는 점에서 해당 문제는 dp라고 할 수 있습니다.
아래의 예시 문자열들의 LCS를 구해봅시다.
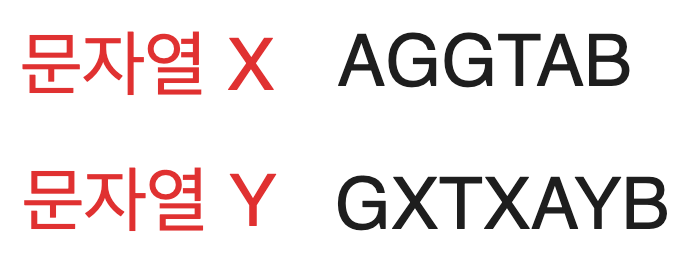
문자열 X는 AGGTAB, 문자열 Y는 GXTXAYB입니다.
1. i = 1, j = 1
X[0] != Y[0] 이므로 LCS[1][1] = max(LCS[0][1], LCS[1][0])입니다.
LCS[1][1] = 0
2. i = 1, j = 2
X[0] != Y[1] 이므로 LCS[1][2] = max(LCS[0][2], LCS[1][1])입니다.
LCS[1][2] = 0
3. i = 1, j = 3
X[0] != Y[2] 이므로 LCS[1][3] = max(LCS[0][3], LCS[1][2])입니다.
LCS[1][3] = 0
계속 진행합니다...
4. i = 1, j = 5
X[0] == Y[4] 이므로 LCS[1][5] = LCS[0][4] + 1 입니다.
LCS[1][5] = 1
5. i = 2, j = 1
X[1] == Y[0] 이므로 LCS[2][1] = LCS[1][0] + 1 입니다.
LCS[2][1] = 1
계속 진행해서 마지막 step의 경우...
6. i = 6, j = 7
X[5] == Y[6] 이므로 LCS[6][7] = LCS[5][6] + 1 입니다.
LCS[6][7] = 4
따라서 LCS는 "GTAB"로 4입니다.
LCS 알고리즘 구현 코드
# lcs
def lcs(X, Y):
m = len(X)
n = len(Y)
LCS = [[0] * (n+1) for _ in range(m+1)]
for i in range(1, m+1):
for j in range(1, n+1):
if X[i-1] == Y[j-1]:
LCS[i][j] = LCS[i-1][j-1] + 1
else:
LCS[i][j] = max(LCS[i-1][j], LCS[i][j-1])
return LCS[m][n]
X = "AGGTAB"
Y = "GXTXAYB"
print(lcs(X, Y))
References
https://www.youtube.com/watch?v=OxsZKLfaWX0&ab_channel=%EB%8F%99%EB%B9%88%EB%82%98
https://www.geeksforgeeks.org/longest-common-subsequence-dp-4/
https://www.youtube.com/watch?v=MeE-GSikiE4&ab_channel=IOIKOREA